Vegetable Classifier Using CNN
Overview
In this project, I built an effective image classifier for the most common vegetables found across the globe. For image classification, I employed the use of a Convolutional Neural Network (CNN) in tandem with a few popular preprocessing steps. This project was purely meant as a learning experience so there is no defining problem statement to support this project. Instead, my goal was to tune and improve my model to maximize performance. The final iteration achieved a training accuracy of 96.73%.
The Data
To start, let's talk about the data. The dataset used can be found on Kaggle here. The data consists of 15 types of common vegetables found throughout the world. The vegetables are- bean, bitter gourd, bottle gourd, brinjal, broccoli, cabbage, capsicum, carrot, cauliflower, cucumber, papaya, potato, pumpkin, radish and tomato. A total of 21000 images from 15 classes are used where each class contains 1400 images of size 224x224 and in *.jpg format. The dataset split 70% for training, 15% for validation, and 15% for testing purpose.

Image Processing & Preparation
To combat overfitting we're going to do a couple things. First, we're going to generate additional training data from existing examples by augmenting them using random transformations of existing images. This is done by randomly rotating the image and altering the contrast. Second, we're going to implement dropout layers in our CNN model. Applying dropout to a layer randomly drops out (by setting the activation to zero) a number of output units from the layer during the training process. Dropout takes a fractional number as its input value, in the form such as 0.1, 0.2, 0.4, etc. This means dropping out 10%, 20% or 40% of the output units randomly from the applied layer.

Model Design and Training
As discussed earlier, the first layers of the model involve image processing steps (normalization & augmentation). This is followed by 3 convolutional, each followed by a pooling and dropout layer. Lastly, the input is flattened and passed through a final dense layer. The optimizer chosen to train the model was Adam. The model was trained for 10 epochs, with a batch size of 32. An early stopping callback was implemented to mitigate the chance of overfitting. The comparison of loss and accuracy between the training and validation datasets can be seen below. I typically would have tried training it for more epochs but my RAM was limited and I didn't want to compromise image resolution.
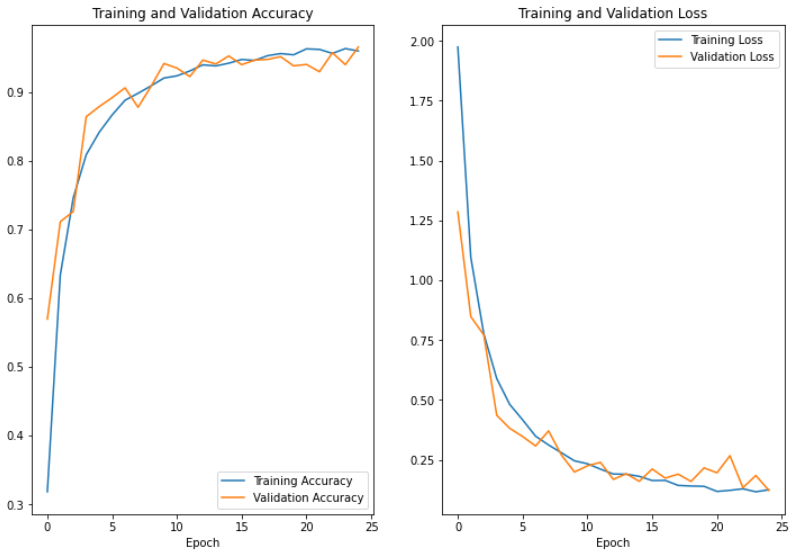
As you can see, there is minimal overfitting, training and validation accuracy & loss are closely aligned. An indicator of overfitting would be if validation accuracy or loss stalls out while training accuracy continues to improve. When this happens it's good practice to reduce the number of epochs, add dropout layers to the model, or try to make the training set more diverse. In fact, we should probably run this model for more epochs to test how far we could go before overfitting (and we could probably increase performance) but Google Colab is limiting my RAM so more epochs will probably crash the runtime.
Evaluation & Results
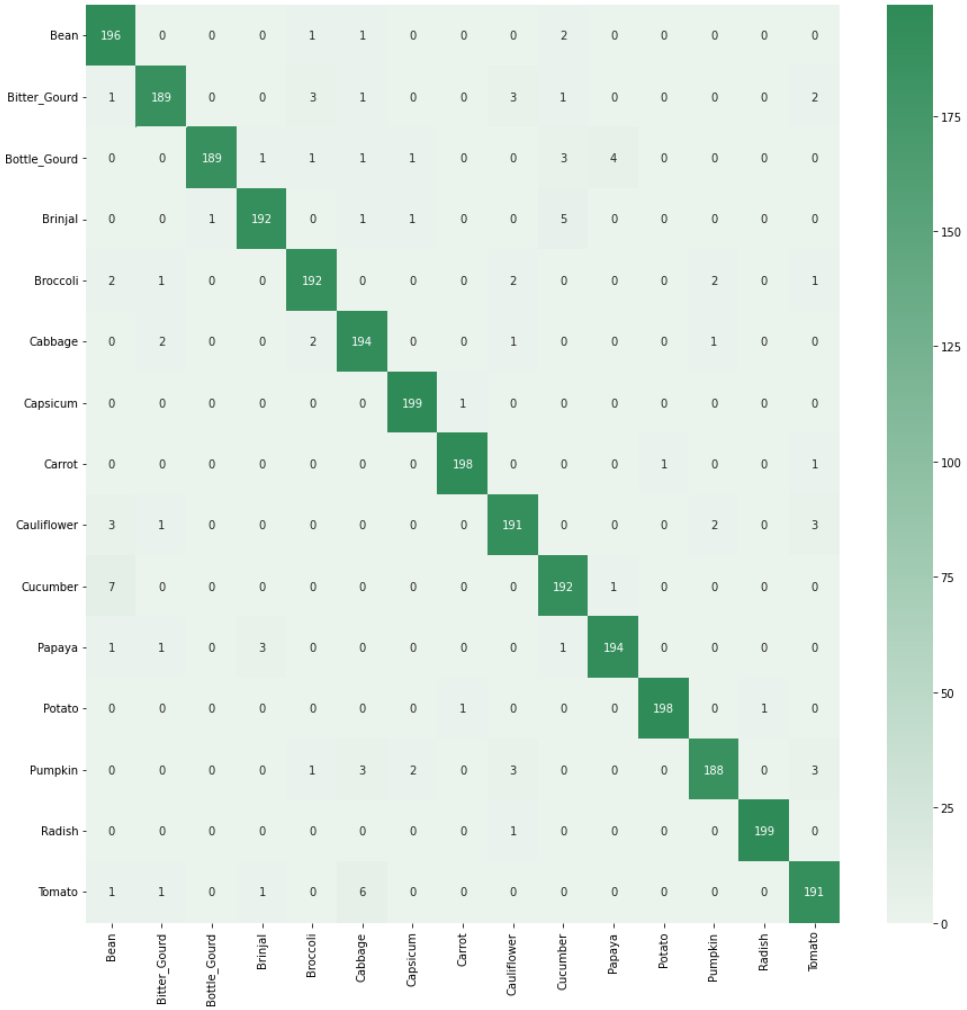
The final iteration of the CNN model achieved an accuracy of 96.73%. Below you can see the classification accuracy specific to each class in addition to a confusion matrix. The model did an all around good job but it was clearly better at recognizing some vegetables more than others The confusion matrix helps make sense of which classes were getting mixed up with each other. For obvious reasons, the vegetables with similar color schemes and shapes got mixed up more often than others. For instance, the bottle gourd and papaya have a very similar shape and color. Overall though, the classifier was pretty accurate across the board, effectively classifying each vegetable with comparable accuracies. This is even more impressive when considering the fact that the this dataset contains vegetables in differing forms (ripe, unripe, picked, still on the plant, busy backgrounds, etc.). This is important when considering the robustness of the classifier because it will be able to accurately classify vegetables while accounting for "real world" variance.

In the future, I want to compare the performance of this CNN to that of a ResNet and VGG16 architectures. However, these model designs are both much more computationally expensive and my current computer would have difficulty training either of them.